Here's an issue I've been struggling with for a few hours.
As you know, BERT models excel at building contextualised embeddings for word pieces in context. To achieve this, a contextualisation process looks at the other word pieces in the input sentence and updates every word piece with regard to these other word pieces. To do this, however, there must first be simple static embeddings for every word piece, which can then be further contextualised (using the static embeddings of the other word pieces).
As such, you'd expect that the static embedding for the word "rock" is the same in the following sentences, since it hasn't been contextualised yet:
- I found a rock.
- I only listen to rock.
However, when we look at the embedding values (only first value shown), we see that the embeddings are in fact different:
0.0072002243 CLS
-0.6297855 I
-0.088253215 found
-0.26929685 a
-0.7464624 rock
0.11356917 SEPvs.
0.0072002243 CLS
-0.6297855 I
-0.24548365 only
-0.92078257 listen
0.056366425 to
0.2555759 rock
0.01896917 SEPCuriously enough, the embedding for I is the same. What's going on? The explanation for this behaviour is very simple. The issue is that it's so simple that you can easily gloss over this.
If we refer to the famous schematic of BERT's input, we see that BERT input does not only consist of token embeddings. Indeed, the input vectors also consist of segment embeddings and position embeddings. These embeddings are crucial in the BERT architecture to differentiate between word pieces, and are thus also added to the input.
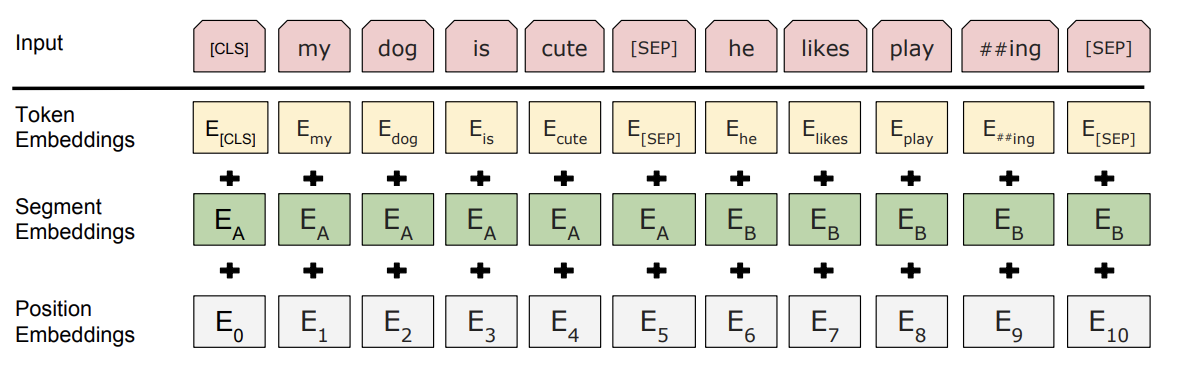
Our word "rock" is not in the same position in the two example sentences, and thus has a different embedding. The word I, however, is in the same position, and therefore the I embeddings are the same. It's that simple.
Moral of the story: never forget what you already know.